Publications
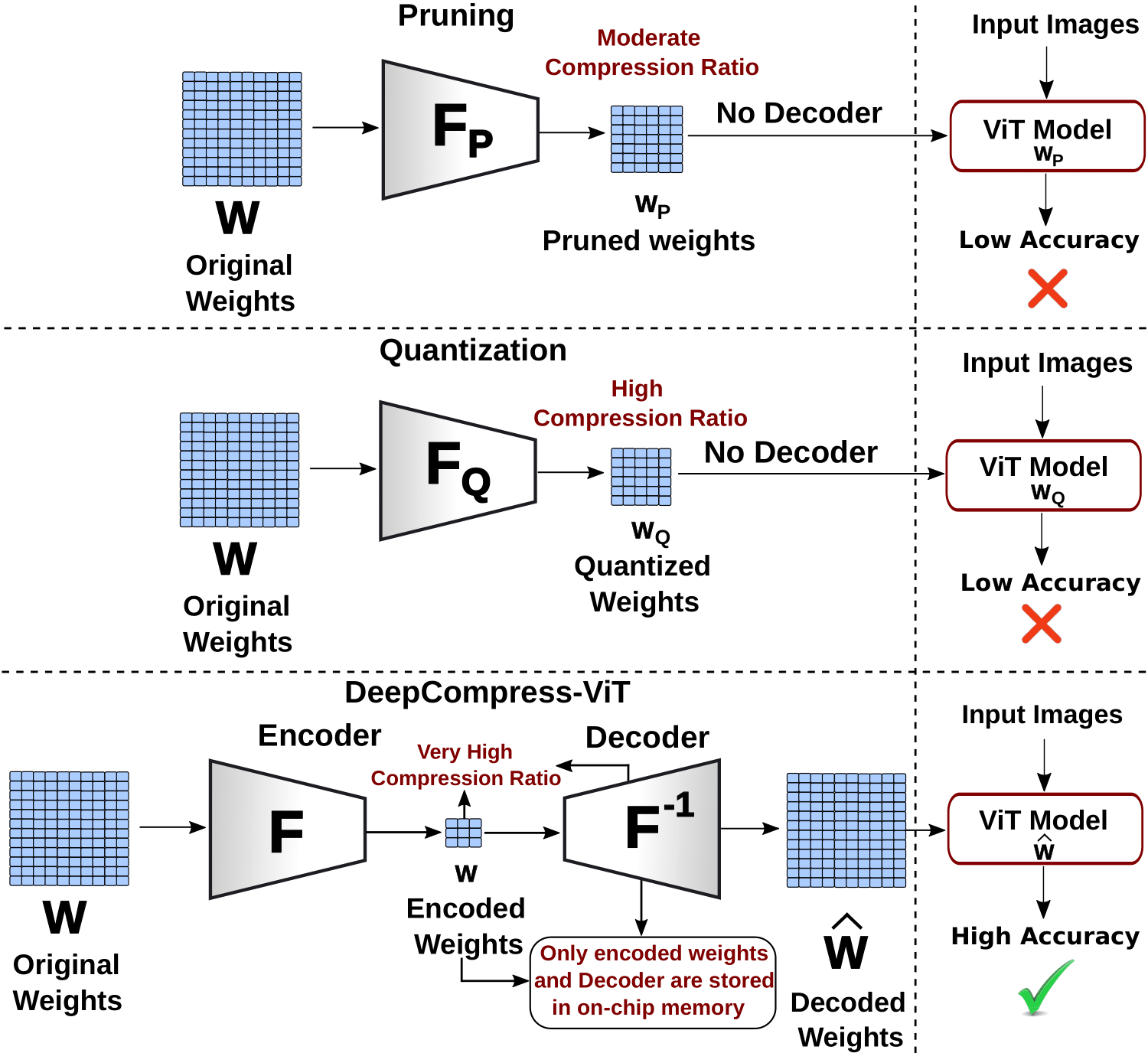
Sabbir Ahmed, Abdullah Al Arafat, Deniz Najafi, Akhlak Mahmood, Mamshad Nayeem Rizve, Mohaiminul Al Nahian, Ranyang Zhou, Shaahin Angizi, and Adnan Siraj Rakin.
DeepCompress-ViT: Rethinking Model Compression to Enhance Efficiency of Vision Transformers at the Edge.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. To appear

Sabbir Ahmed, Ranyang Zhou, Shaahin Angizi, and Adnan Siraj Rakin.
Deep-TROJ: An Inference Stage Trojan Insertion Algorithm through Efficient Weight Replacement Attack.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
link
link
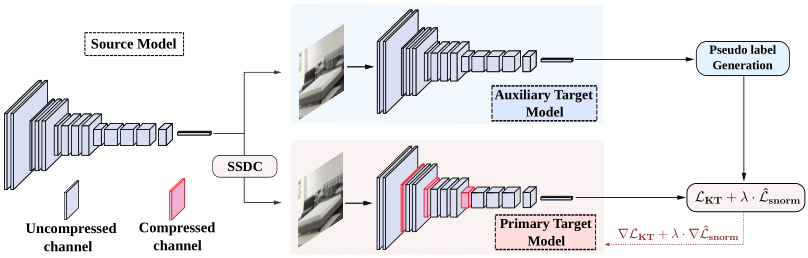
Sabbir Ahmed, Abdullah Al Arafat, Mamshad Nayeem Rizvee, Rahim Hossain, Zishan Guo, and Adnan Siraj Rakin.
SSDA: Secure Source-Free Domain Adaptation.
International Conference of Computer Vision (ICCV), 2023.
link
link
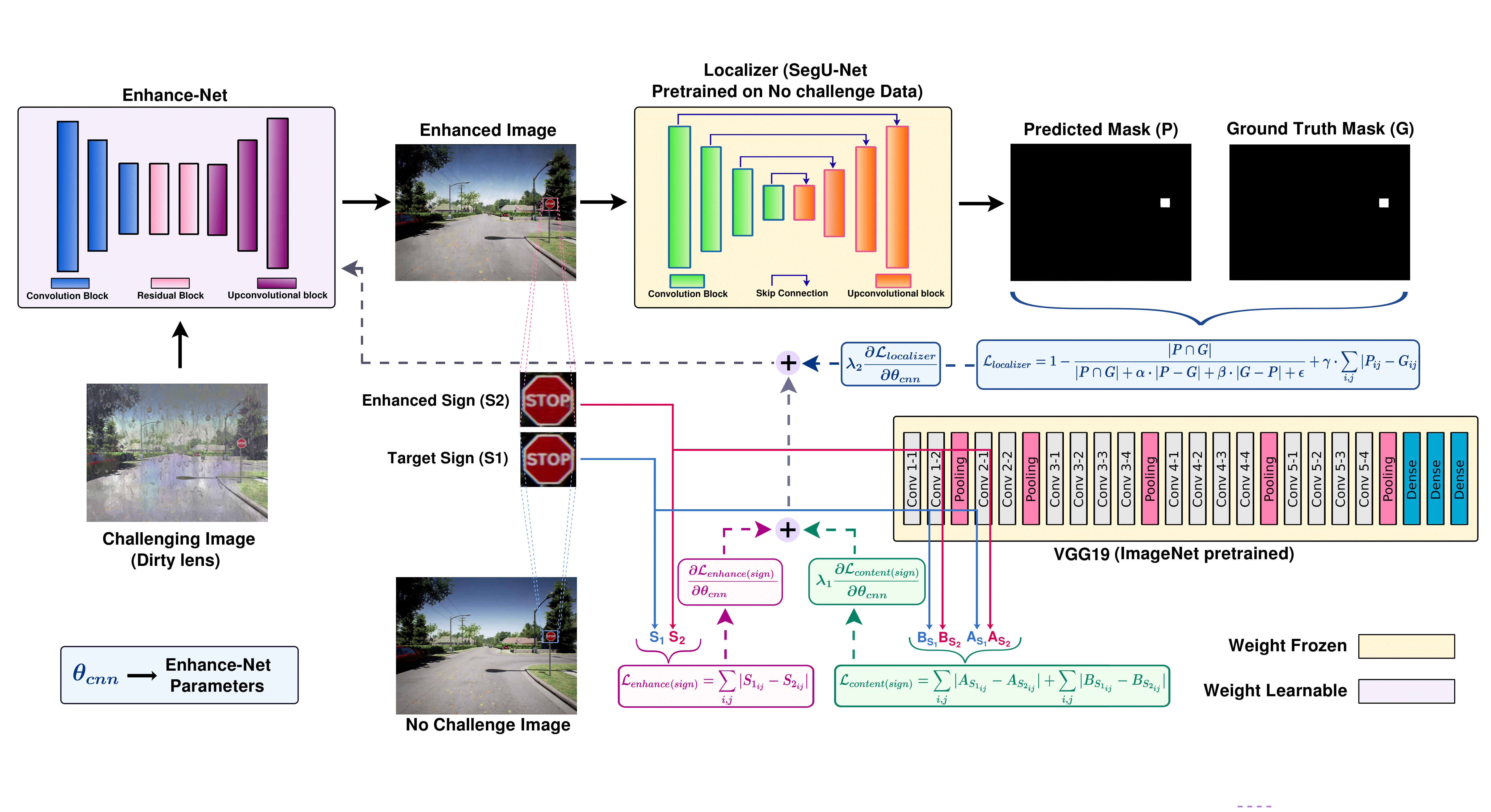
Sabbir Ahmed, Uday Kamal, and Md Kamrul Hasan.
DFR-TSD: A deep learning based framework for robust traffic sign detection under challenging weather conditions.
IEEE Transactions on Intelligent Transportation Systems (T-ITS), 2021.
link
link